Building Multi-Agent GoHighLevel AI Stacks: Architecture, Cost, and Failure Modes
Single-agent GoHighLevel AI builds are the 2024 version of "we've got AI in the funnel". They were a useful first step. They are no longer the bar. The agencies winning in 2026 are running multi-agent GoHighLevel AI stacks — orchestrated specialists that handle inbound triage, qualification, booking, follow-up, support, and reactivation, with handoffs between them that look more like a small inside-sales team than a chatbot.
This is the implementation guide we wish existed when we started building these stacks for clients. It covers architecture, the real cost stack, the failure modes that take a "go-live" build offline, and the decision framework we apply on every project. Aussie English throughout. Written for founders, agency owners, and operators who already understand basic GoHighLevel AI agents and need the next layer of depth. If you're earlier in the journey, start with our GoHighLevel AI pillar page.
Why multi-agent stacks beat single-agent agents
A single agent prompted to "be a helpful sales assistant for our business" tries to do six jobs and does each one badly. The classic symptoms:
- It books strategy calls for tyre-kickers because the qualification logic is buried in a system prompt nobody updates.
- It hallucinates pricing because pricing isn't in its context window.
- It hands off to a human in the wrong situations because the handoff trigger is "user asks for a human".
- It can't access conversation history older than the current message context, so it asks for information you already have on the contact.
- It runs every inbound message through the same expensive model, including the 60% of messages that are "thanks" or "great".
Multi-agent stacks fix this by giving each agent one job, one set of tools, one model size appropriate to the task, and one explicit handoff condition. The architecture is harder to set up. The economics, conversion rates, and customer experience are step-changes better.
A real client metric: we replaced a single-agent setup for a coaching agency with a four-agent stack in March 2026. Inbound message cost per conversation dropped 71%. Call-booking rate per inbound conversation lifted from 6.2% to 14.8%. The founder's "I have to babysit the AI" load dropped to one weekly review.
The reference architecture
The architecture we build, refined across roughly forty live deployments, looks like this:
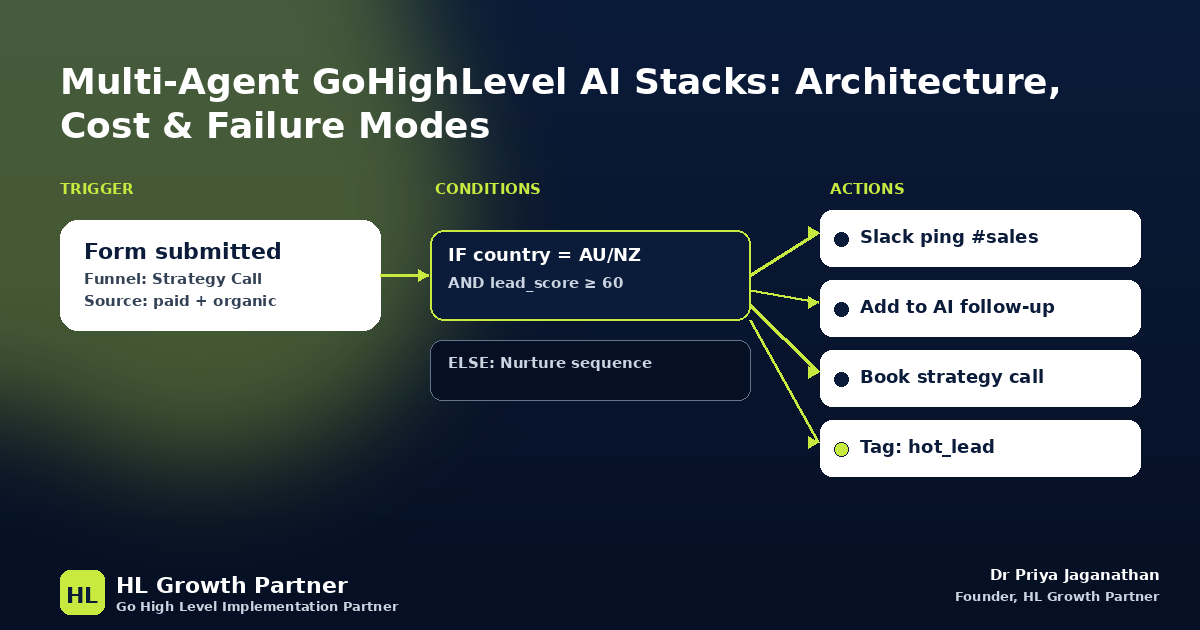
- Triage agent (small model). Receives every inbound message. Classifies intent into one of: support, sales enquiry, existing customer, pricing question, partnership, out-of-scope, spam. Does not respond to the customer. Outputs a structured intent + confidence score and routes.
- Sales agent (medium model). Handles top-of-funnel sales conversations. Has tool access to: knowledge base, pricing table, calendar booking, lead-score update, opportunity creation. Cannot quote bespoke pricing. Explicit handoff when scope exceeds defined offers.
- Qualification agent (medium model). Triggered by the sales agent when a lead expresses intent to book. Asks a short qualification script (3–5 questions), updates custom fields, decides whether to book on the senior calendar or the junior calendar. Can refuse to book.
- Support agent (small model). Handles existing-customer enquiries. Tool access to: knowledge base, ticket creation, account lookup. Escalates to a human via internal Slack when confidence drops or the customer asks twice.
- Reactivation agent (small model, async). Runs on a schedule, not on inbound message. Scans contacts who haven't been touched in 60+ days, drafts a personalised one-line reactivation message, queues it for human approval before sending.
- Voice agent (paid, separate). Handles outbound dialled follow-up on missed appointments and high-intent leads. Logs the conversation transcript back into GHL.
Each agent has its own GoHighLevel AI agent definition, its own system prompt, its own tool list, and (this matters) its own model budget.
How the agents hand off
The handoff layer is where most builds quietly fail. We use four explicit handoff types:
- Intent handoff — triage agent classifies the message, drops the contact into a workflow that routes them to the right specialist agent.
- Tool handoff — sales agent says "I'll get you booked" and calls a tool that triggers the qualification agent's workflow.
- Confidence handoff — any agent whose response-confidence score falls below 0.7 escalates to a human via internal Slack with the conversation context attached.
- Time-bound handoff — if an agent has been in conversation for more than 90 seconds without a successful tool call, escalate. (Long agent monologues are usually a sign the agent is lost.)
Each handoff is implemented as a GHL workflow with a clear trigger and a single responsibility — the same disciplined trigger architecture we cover in the workflows pillar. No agent ever silently morphs into another role — that's where customers feel the seams.
Implementation example — the four-agent coaching stack
A real build, simplified. Client: an online coaching business doing $80K/month in revenue with 600 inbound conversations per week.
Triage agent prompt skeleton: "You are the routing layer for {client_brand}. You will receive a single inbound message and the last 30 days of conversation summary. Classify the intent into one of: pricing, booking, support, existing_member, partnership, out_of_scope. Return a JSON object with intent, confidence, and reason. Do not respond to the customer."
Sales agent prompt skeleton: "You are {first_name_from_brand}, a senior client success representative at {client_brand}. Your only job is to answer sales questions about our coaching programs and surface the right next step. You have access to: pricing tool, knowledge base tool, booking handoff tool. You may quote any price in the pricing tool. You may NOT invent pricing. If asked about pricing not in the tool, say 'Let me get someone to confirm — what's your phone number?' and trigger handoff. If the customer expresses booking intent twice or asks 'how do I get started', trigger qualification handoff."
Qualification agent prompt skeleton: "You are running a short qualification call (in text) for {client_brand}. Ask exactly these four questions, one at a time, waiting for an answer: 1) What's your current monthly revenue? 2) What's the biggest bottleneck right now? 3) Have you tried a coach before? 4) When would you ideally start? After all four answers, score the lead per the rubric (>$15K MRR + clear bottleneck = senior calendar; otherwise junior calendar). Book on the appropriate calendar. Confirm in plain language."
Support agent prompt skeleton: "You handle existing-customer support for {client_brand}. You have access to a knowledge base and a ticket-creation tool. Always look up the contact's plan before answering. If you cannot find the answer in the knowledge base in two queries, escalate to a human via Slack with the conversation transcript."
Each prompt is paired with a tool list, a model choice (small for triage and support, medium for sales and qualification), and explicit handoff rules.
The real cost stack
The honest cost breakdown for a multi-agent stack handling 600 conversations a week (roughly 2,600/month) in 2026:
- Triage agent — 2,600 inferences × small model token cost (~$0.002 per inference all-in) = ~$5/month.
- Sales agent — ~1,000 conversations × ~8 turns each × medium model (~$0.012 per turn) = ~$96/month.
- Qualification agent — ~300 conversations × ~6 turns × medium model = ~$22/month.
- Support agent — ~700 conversations × ~5 turns × small model = ~$7/month.
- Reactivation agent — ~500 drafts × small model = ~$1/month (drafts only; humans approve).
- Voice agent — ~150 calls × $0.06/minute average × 4-minute average = ~$36/month.
- GHL AI agent platform fees — ~$60/month at 2026 pricing for this volume.
- Webhook/workflow fees — included in plan.
Total infra spend: ~$227/month. Total agency-owner time to operate after build: ~2 hours/week for review and tuning.
Compare to the alternative: a part-time SDR at $25/hour for 30 hours/week = $3,000/month, plus management overhead. The economics are obvious. The risk profile is different — agents fail differently to humans and you have to design for it.
Named failure modes — what actually breaks
After 40+ live builds, these are the failure modes we name and design around explicitly.
Failure 1 — Context loss across handoffs. Sales agent collects information, qualification agent doesn't see it, asks the same questions, customer churns. Fix: every handoff must pass a structured conversation-summary object, not just the message history.
Failure 2 — The "polite confirmation loop". Customer says "yes, sounds good", agent says "great, let me get that organised", customer says "thanks", agent says "you're welcome, do you need anything else?", customer says "no", agent says "happy to help"… for six turns. Fix: explicit exit-conversation tool the agent can call when the customer has acknowledged completion.
Failure 3 — Hallucinated pricing. Sales agent quotes a number that isn't in the knowledge base. Customer commits to that number. Awkward call required from a human. Fix: pricing must be accessed only via a structured tool that returns from a single source-of-truth table. The system prompt must explicitly forbid invention.
Failure 4 — Confidence-score drift. An agent's response-confidence score is high even when the answer is wrong, because the model is confident-sounding by default. Fix: don't rely on the model's self-assessed confidence alone. Layer a secondary check (was a tool call made? Was the customer's question semantically answered?) before treating "confident" as "correct".
Failure 5 — The 3 a.m. customer-service spiral. A confused customer messages at 3 a.m. The support agent answers six times, gets it wrong, the customer escalates publicly. Fix: every customer-facing agent has an explicit "I'll get a human onto this in the morning" path, and an after-hours mode that uses it earlier.
Failure 6 — Webhook silent failure. An agent calls a tool to create an opportunity, the webhook fails silently, the conversation continues as if the opportunity exists, the customer thinks they're booked. Fix: every tool call must return a structured success/failure response that the agent reads before continuing the conversation.
Failure 7 — Sub-account drift in SaaS Mode multi-tenant builds. You ship the agent stack as a snapshot to 50 SaaS Mode sub-accounts. Three months later, twelve of them have local customisations that diverge from the parent. A bug fix to the parent doesn't propagate. Fix: version your agent prompts in a central source-of-truth (a Notion page or a GitHub gist), and run a monthly drift audit script.
How to roll out a multi-agent stack (step-by-step)
- Map the inbound flows you actually have. Pull six weeks of inbound conversations. Cluster them by intent. The clusters become your agent roster, not the other way around. Don't design an agent for an intent that occurs twice a month.
- Write the triage agent first. It is the cheapest, simplest, and most leveraged piece. If your triage agent classifies well, every downstream agent has a clean job.
- Build agents one at a time. Ship one agent into a test sub-account, watch 100 conversations, fix, then ship the next. Building all four in parallel and going live in one day is the single most common cause of multi-day post-launch outages.
- Wire up observability before you ship. Every inbound message, every classification, every tool call, every handoff must log to a place you can read. A simple Google Sheet via webhook works for the first 1,000 conversations. Move to a real dashboard after that.
- Run a weekly review for the first 8 weeks. Read 30 random conversations. Score each against: was the right intent classified, was the right tool called, was the customer happy at the end, was a human escalation triggered correctly. Tune the prompts based on the patterns you see.
- Refactor monthly. Multi-agent stacks rot in production. Customers' patterns drift, your offers change, the underlying model gets updated. A 30-minute monthly tune-up keeps performance from sliding.
Decision framework — should you build a multi-agent stack?
The honest answer is: only if your volume justifies the build cost.
| Volume per week | Right architecture |
|---|---|
| < 50 inbound conversations | Don't build AI. Answer them yourself or use a simple chatbot. |
| 50–200 | Single-agent stack with strong handoff to human. |
| 200–500 | Single-agent or 2-agent (triage + sales). |
| 500–2,000 | Full multi-agent stack — 4 agents, real ROI. |
| 2,000+ | Multi-agent stack + bespoke observability dashboard + dedicated review process. |
Build cost (when we do it): 14–21 calendar days for a 4-agent stack with snapshot deployment to one sub-account. SaaS Mode multi-tenant builds add another 10–14 days for templating and drift controls. If you want to see what that looks like end-to-end, our implementation onboarding page lays out the build cadence.
Alternatives
If a multi-agent stack is the wrong tool for your stage, the working alternatives are:
- Single-agent with strong handoff — covers most agencies under 200 conversations/week.
- Workflow-driven scripted flows (no LLM) — for highly structured intake (e.g. quote requests for trades). Cheaper, more predictable, deliberately less flexible.
- Human-only with AI drafting — keep humans in the loop, use the AI to draft replies in the background. Slower, but the conversion economics for high-ticket sales sometimes justify it.
If you're not sure which stage you're at, the answer is "smaller than you think". Almost every agency we audit has over-built the AI layer and under-built the workflow layer below it.
Frequently asked questions
What's the difference between GoHighLevel AI Employee and a custom multi-agent stack?
GHL AI Employee is the productised single-agent layer — fast to set up, limited in routing logic and tool access. A custom multi-agent stack uses the underlying AI agent platform plus workflows to give each agent one job and explicit handoffs. AI Employee is a great place to start; a multi-agent stack is where you go when conversation volume and conversion economics justify the build.
Which model size should I use for which agent?
As of May 2026: triage and support — small models (typically 4–8B class) are fast and accurate enough. Sales and qualification — medium (32–70B class) for nuance. Voice agents use whatever GHL Voice supports natively. Don't pay medium-model rates for a triage classifier.
How do I handle the customer asking for a human?
Always honour it on the first ask. Don't gate behind "what do you need them for?" — that frustrates the customer and makes the AI feel evasive. The handoff is the trust signal, not the failure.
Can I use my own LLM (OpenAI / Anthropic / open source) instead of GHL's?
Yes — via webhooks to your own endpoint. You lose some of the native conversation-state plumbing but you gain full control of the model and the cost. We typically run this hybrid for clients with regulated industries or specialised knowledge bases.
How do you stop the AI from being too friendly / too pushy?
Set explicit tone-of-voice anchors in each prompt with examples. "We are calm, not enthusiastic. We do not use exclamation marks unless the customer used one first. We do not say 'amazing' or 'fantastic'." It works.
How do I know when an agent prompt needs updating?
Two signals: conversion on the post-agent action drops sustainably (lower booking rate week-on-week), or the percentage of conversations escalated to humans climbs. Both indicate the agent is no longer handling the inbound shape correctly.
Can I A/B test agent prompts?
Yes — run two GHL AI agent definitions in parallel and route alternate conversations via a workflow split. Measure on a single outcome metric (booking, ticket resolved, customer satisfaction score) not on internal proxies.
What's the smallest viable multi-agent build?
Triage + Sales + Support — three agents. That's the minimum useful split because it separates inbound classification from outbound conversation and isolates the existing-customer cohort. Most agencies grow into the fourth (qualification) and fifth (reactivation) agents over the first six months.
Do multi-agent stacks work for B2C as well as B2B?
Yes, but the agent count usually drops to two (triage + service). B2C inbound volume is higher, intent variance is lower, and the qualification layer is usually unnecessary.
If you want a multi-agent GoHighLevel AI stack built, snapshot-templated, and observability-instrumented inside your business — that's exactly the work we do. The first conversation is a 30-minute architecture review where we map your inbound shape to the right agent roster.
